
Context Engineering - Foundational Concepts and Mechanisms
Effective context engineering relies on several core technical mechanisms that enable Large Language Models (LLMs) to acquire, process, and utilize external information. These mechanisms are crucial for extending the capabilities of LLMs beyond their initial training data.
The Role of In-Context Learning (ICL)
In-context learning (ICL), also known as few-shot learning or few-shot prompting, is a powerful technique where task demonstrations are integrated directly into the prompt in a natural language format. A defining characteristic of ICL is that the model learns to address a new task during inference without any gradient updates or fine-tuning of its underlying parameters. Instead, the model learns by analogy, generalizing from a small number of input-output examples provided within the prompt. It is important to note that the knowledge acquired through ICL is transient; it is not persistently stored post-inference, which ensures the stability of the model’s parameters. This transient nature of ICL knowledge is a critical detail. It means ICL is not about embedding new knowledge into the model’s long-term memory or parameters, but rather about dynamically adapting the model’s pre-trained capabilities to a specific task at inference time. This suggests that ICL is best suited for flexible, on-the-fly task customization and generalization from patterns, rather than for ensuring factual accuracy from a specific, evolving knowledge base. This limitation highlights the complementary role of other techniques like Retrieval-Augmented Generation (RAG) for persistent, verifiable knowledge.
The efficacy of ICL stems from its ability to leverage the extensive pre-training data and the expansive scale inherent to LLMs. Larger models, trained on more extensive datasets, consistently exhibit superior ICL performance. This suggests that the model isn’t truly “learning” entirely new concepts from the few-shot examples but rather activating and re-weighting latent concepts and patterns already encoded during its massive pre-training. The examples merely serve as cues to guide the model to infer these latent concepts and apply its existing knowledge to the new task. This deepens the understanding of ICL as a sophisticated form of pattern matching and analogy drawing within the model’s existing knowledge manifold, rather than true novel learning.
ICL offers significant advantages, including its flexibility to adapt to various tasks without requiring costly retraining, reduced computational overhead compared to fine-tuning, data efficiency (as it can be effective with limited examples), and an intuitive interaction model through natural language examples. Its approach mirrors human cognitive reasoning processes, contributing to its intuitive nature for problem-solving. ICL is making a notable impact across various Natural Language Processing (NLP) tasks, such as sentiment analysis (by providing example sentences and their sentiments), customized task learning (by showing a few examples), and language translation (by providing input-output pairs).
Despite its promise, ICL does have limitations. Its effectiveness can be constrained when task complexity increases, even when sufficient demonstrative examples are provided. Furthermore, it is limited by the quality and coverage of the few-shot examples, sometimes generating outputs that are too similar to the input examples or failing to capture the nuanced details of the input passage. Recent advancements in ICL research include “context-enhanced learning,” a gradient-based analog of ICL, which has shown the potential for exponentially more sample-efficient learning when the model is capable of ICL. Expanded context windows in modern LLMs also enable “many-shot ICL,” allowing for more examples and further improving performance on complex tasks. Research continues to explore automated prompt generation and optimization techniques for ICL, as well as the expansion of ICL to multimodal data types.
Retrieval-Augmented Generation (RAG): Principles and Evolution
Retrieval-Augmented Generation (RAG) is a transformative technique that significantly enhances Large Language Models (LLMs) by enabling them to retrieve and incorporate external, up-to-date information before generating responses. This approach effectively supplements the information derived from the LLM’s pre-existing, static training data. RAG serves to bridge the gap between the vast, but potentially outdated, knowledge embedded in general-purpose LLMs and the critical need for precise, contextually accurate, and current information in real-world applications. The repeated emphasis on RAG’s ability to reduce “hallucinations” and provide “accurate, up-to-date, and contextually relevant” information highlights its fundamental role in making Generative AI reliable and trustworthy for practical deployment. Without RAG, LLMs are prone to factual inaccuracies, which severely limits their utility in domains requiring high fidelity, such as legal, medical, or financial applications. RAG transforms LLMs from impressive language generators into “grounded” knowledge systems.
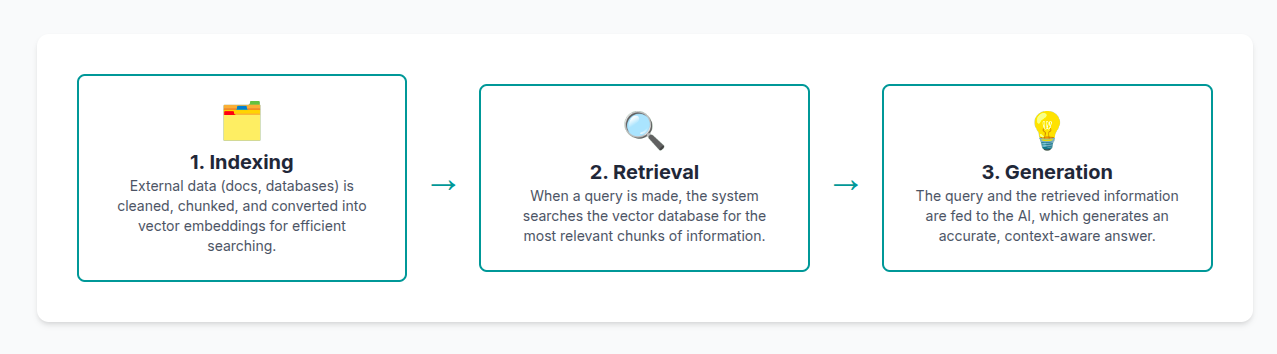
The mechanism of RAG typically involves three main steps:
Indexing: Raw data from diverse formats, such as PDFs, HTML, or Word documents, is first cleaned, extracted, and converted into a uniform plain text format. To accommodate the context limitations of language models, this text is then segmented into smaller, digestible “chunks.” These chunks are subsequently encoded into vector representations using an embedding model and stored in a vector database. Notably, knowledge graphs can also be vectorized and stored for retrieval, offering a more recognizable structure than mere strings of text, which can aid in retrieving more relevant facts for generation.
Retrieval: When a user submits a query, a dedicated document retriever searches for relevant content from available external sources, including databases, uploaded documents, or web sources. This search is primarily conducted using vector embeddings to find the most semantically similar documents or chunks to the user’s query. Optional “reranker” components can further evaluate the retrieved documents to determine their precise relevance to the question, providing a refined relevance score for each.
Generation: The information retrieved in the previous step is then incorporated into the LLM’s input, a process sometimes referred to as “prompt stuffing”. This augmented input guides the model’s response, ensuring that the generated text is grounded in the external data rather than solely relying on its internal, potentially outdated, training knowledge.
RAG offers several significant advantages:
Enhanced Accuracy and Reduced Hallucinations: By grounding responses in verifiable external knowledge, RAG substantially reduces the problem of LLMs generating factually incorrect content or “hallucinations”.
Access to Up-to-Date Information: It enables LLMs to access and utilize dynamic, real-time data beyond their original training set, lessening their reliance on static datasets that can quickly become outdated.
Cost and Efficiency Savings: RAG minimizes the need to frequently retrain LLMs with new data, leading to considerable savings in computational and financial costs.
Verifiability and Trust: A key benefit of RAG is its ability to allow LLMs to include sources in their responses, enabling users to verify the cited information. This transparency is crucial for building trust and ensuring accountability in AI-generated content.
Domain Adaptation: RAG facilitates continuous knowledge updates and the seamless integration of domain-specific information, allowing general LLMs to perform effectively in specialized fields.
The evolution of RAG research extends beyond merely providing information during the inference stage; it increasingly incorporates LLM fine-tuning techniques. Future RAG systems are expected to integrate adaptive retrieval mechanisms that dynamically adjust based on user intent and query complexity, optimizing source selection in real-time. To address the limitations of traditional single-step retrieval, which can suffer from context fragmentation and incomplete processing, advancements include multi-step dynamic retrieval techniques like CoRAG (Chain-of-Retrieval Augmented Generation).
CoRAG introduces rejection sampling for intermediate retrieval chains and incrementally validates each retrieved document, while MetaRAG incorporates metacognitive self-reflection to dynamically evaluate and refine retrieval performance. Future directions also involve scalable architectures for cross-modal retrieval fusion, integrating text, images, and structured data. The convergence of RAG and Agentic AI for complex problem solving is a significant trend. The evolution of RAG towards “multi-step, dynamic retrieval techniques” like CoRAG and MetaRAG, and its integration with “Multi-Agent Systems”, strongly suggests a powerful synergy with Agentic AI. Agentic AI aims for autonomous behavior and complex task execution requiring reasoning, planning, and reflection. RAG, by providing dynamic, verifiable, and context-aware information, becomes the critical “sensory input” for these intelligent agents, enabling them to navigate complex, real-world problems that require continuous information gathering and refinement. This points to a future where RAG is not just a feature but a foundational component of intelligent, goal-oriented AI systems. Research also aims for self-improving RAG models through meta-learning and RL-optimized retrieval agents that learn from historical queries.
Benefits of RAG in Generative AI
| Benefit | Explanation/Impact |
|---|---|
| Enhanced Factual Accuracy | Directly addresses factual errors in AI responses, making them more reliable. |
| Reduced Hallucinations | Prevents the generation of unsupported or fabricated content by grounding responses in external data. |
| Access to Real-time Information | Ensures responses are current and relevant by pulling dynamic data beyond static training sets. |
| Cost Efficiency (Reduced Retraining) | Minimizes the need for expensive and time-consuming LLM retraining with new data. |
| Source Verifiability/Transparency | Builds trust by allowing users to check the cited sources for generated information. |
| Domain-Specific Adaptation | Tailors general LLMs to specific industries, internal knowledge bases, and proprietary data. |
| Improved Relevance | Provides precise, contextually appropriate answers by focusing on information most pertinent to the query. |
The Importance of Structured Data Integration
While Large Language Models (LLMs) excel at processing unstructured text, the quality and reliability of their generated content, particularly in complex and high-stakes fields like healthcare and finance, are profoundly influenced by the integration of structured data. Structured data is information organized in a predictable format, typically within tables that have defined fields, making it readily searchable and efficiently processable by algorithms. Common formats include CSV files, Excel spreadsheets, relational databases (SQL), JSON, XML, and Google Sheets. In contrast, unstructured data, such as free-form text, images, or videos, lacks a specific format and requires significantly more effort for machines to interpret and utilize effectively.
Structured data is crucial for Generative AI because its adherence to a consistent schema simplifies the process for models to understand and use information effectively. This organization enables AI models to readily identify patterns, relationships, and relevant features, which in turn leads to more coherent and reliable outputs. The repeated emphasis that structured data is “crucial for the quality of the generated content,” enabling “accuracy, consistency, and trustworthiness” highlights its fundamental role in making Generative AI reliable and trustworthy for real-world applications. For enterprise applications, especially in regulated or high-stakes domains, the reliability and verifiability of AI outputs are paramount. Structured data provides the necessary ground truth, schema, and traceability that unstructured data alone cannot guarantee, making it a prerequisite for deploying Generative AI in critical business processes.
Key benefits of structured data for Generative AI include:
Enables Automation: Organized data allows systems to easily locate information, apply rules and templates, and process large volumes without human intervention. An example of this is the generation of thousands of real-time sports result summaries.
Reduces Errors and Ambiguity: Structured data minimizes ambiguity, helping AI identify items by their specific context (e.g., distinguishing “goals” from “minutes played”) and avoiding confusion in names, dates, or quantities, which results in more accurate and coherent content.
Improves Traceability and Control: With well-structured data, the exact source of each fact in the generated text can be known. This facilitates auditing and validation of results, which is critically important in sectors like pharmaceuticals, finance, or journalism, and allows for the application of filters, comparisons, and validation rules.
Supports Multilingual and Personalized Content: Generative AI systems can reuse the same data structure to generate content in multiple languages, adapt texts for different audiences (e.g., more technical vs. more general), or shift focus without altering the underlying database.
Integrates Easily with Tech Systems: Structured data is highly compatible with APIs, databases, spreadsheets, and dashboards, supporting smooth, continuous workflows and enabling automatic updates from external sources.
Efficiency: Algorithms can rapidly access and analyze structured datasets due to their organized nature. This accelerates the learning process for Generative AI, significantly cutting the time needed to train and fine-tune models, thereby enabling quicker deployment of AI solutions and providing a competitive edge in the market.
Enhanced Decision-Making: Clear and organized data directly contributes to Generative AI systems generating more accurate insights and predictions, which is vital for informed decision-making.
Despite these benefits, integrating structured data presents several challenges:
Unstructured Data Processing: While structured data is ideal, many companies possess vast amounts of unstructured data that require significant processing effort to prepare for AI systems.
Data Silos: The isolation of valuable data across different departments or systems is a major impediment to effective AI applications. Overcoming these data silos necessitates integrating disparate systems and fostering a culture of data sharing within the organization.
Scalability: As businesses grow, maintaining and scaling structured data systems becomes increasingly complex. Data architectures must be designed for flexibility and scalability from the outset to handle larger volumes or more complex data relationships, preventing performance bottlenecks that could affect Generative AI models.
Managing Diverse Information Sources: Integrating disparate, heterogeneous information sources, especially when semantic conflicts arise, is a significant technical and organizational challenge. This often requires robust ontology engineering methodologies to formalize and reason about dynamic knowledge and context dependencies.
Resource Demands: Effectively managing structured datasets and building complex context pipelines demands substantial time and a team of skilled personnel.
The challenges highlighted, such as “data silos,” “scalability,” and the need for “skilled personnel”, extend beyond purely technical solutions. They point to significant organizational and cultural hurdles. Effective structured data integration for context engineering requires not just technical tools but also robust data governance policies, inter-departmental collaboration, and investment in data architecture and talent. This suggests that the success of context engineering in an enterprise is as much an organizational transformation challenge as it is a technological one. Furthermore, the mention of “context logic” for integrating disparate, heterogeneous information sources and resolving “semantic conflicts” points to a deeper challenge than just technical integration. It highlights the need for formal methods to represent and reason about the meaning of data within different contexts. This suggests that future advancements in context engineering will involve not just data pipelines, but also semantic layers and ontological frameworks that allow AI systems to understand and reconcile diverse knowledge representations, ensuring coherent and accurate reasoning across complex data landscapes.
Types of Enterprise Context
| Context Type | Description |
|---|---|
| Data & Schema Context | Database schemas, metrics definitions, lineage diagrams, entity mappings. Critical for data reasoning. |
| Code & Technical Context | Code repositories (GIT), APIs, system/architecture design documents, developer workflows (build/test/deploy). Essential for coding copilots and agent debugging. |
| Infrastructure & Operational Context | System state, failure logs, uptime, deployments, CI/CD status. Needed for agents acting in live systems to plan safely. |
| Compliance & Security Context | Data governance rules, access policies, PII boundaries, audit logs, regulatory mappings (GDPR, HIPAA). Essential for trust and risk management. |
| Business & Domain Context | Top-level KPIs and OKRs, domain-specific logic, product/feature taxonomies, broad company goals. Provides holistic meaning and tailoring. |
| Financial Context | Revenue metrics (ARR, MRR), cost structures, pricing models, forecasts, marketing budgets. Foundational for decision-making. |
| Customer & User Context | Account hierarchies, user roles, behavioral data, segmentation logic, feedback, CRM data. Vital for personalization and customer-facing agents. |
| Organizational Context | Team structures, roles, ownership metadata, acronyms, internal norms. Defines “who owns what.” |
| External Market & Competitor Context | Market trends, competitor activity, industry benchmarks, third-party and public data sources. Powerful for strategic planning. |
References:
- What is In-context Learning, and how does it work: The Beginner’s Guide - Lakera AI
- What is In-Context Learning? How LLMs Learn From ICL Examples - PromptLayer
- Assessing the Limits of In-Context Learning beyond Functions using Partially Ordered Relation
- Assessing the Limits of In-Context Learning beyond Functions using Partially Ordered Relation
- Leveraging In-Context Learning and Retrieval-Augmented Generation for Automatic Question Generation in Educational Domains
- On the Power of Context-Enhanced Learning in LLMs
- Retrieval-augmented generation - Wikipedia
- What is retrieval augmented generation - SuperAnnotate
- Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
- Retrieval-Augmented Generation for Large Language Models: A Survey
- Truth-Aware Context Selection: Mitigating the Hallucinations of Large Language Models Being Misled by Untruthful Contexts
- Context and Layers in Harmony: A Unified Strategy for Mitigating LLM Hallucinations - MDPI
- Retrieval-Augmented Generation: The Definitive Guide - Chitika
- Generative to Agentic AI: Survey, Conceptualization, and Challenges
- Real-World Use Cases of Retrieval-Augmented Generation (RAG) in Gen AI
- What is structured data and why it’s crucial for generative AI - Narrativa
- How Does Structured Data Benefit Generative AI? - GigaSpaces